
A data management workflow of biodiversity data from the field to data users
Rachel A Hackett, Michael W Belitz, Edward E Gilbert, And Anna K Monfils
Article Contributed by: Rachel A Hackett and Michael W Belitz
Valuable, broad-scope questions can be answered with biodiversity data in biogeography, climatology, ecology, evolution, phylogenomics, among other topics (Chapman, 2005; Soltis et al., 2018). Results of these questions can be applied to conservation management and inspire future research questions. The data used to answer such questions can be collected directly in the field, mined from other sources (i.e., legacy data), or some combination thereof.
Despite the increased use of biodiversity data, it was estimated that less than one percent of ecological data meet FAIR data principles (findable, accessible, interoperable, and reusable; Reichman et al., 2011). Data not meeting these principles are unlikely to be used to answer questions beyond the original data collector’s vision. Unfindable or inaccessible data is likely to be lost or forgotten, while findable and accessible data not delivered in interoperable or reuseable practices are likely to be removed before analysis by other data users (Heidorn, 2008; Hampton et al., 2015; Cheruvelil and Soranno, 2018). There are a multitude of new applications emerging that use legacy data, and advances occur in data sharing infrastructure, computational power, and statistical methods. The value of data can long outlive the goal of the original data collector and contribute to the scientific and management communities at large, if FAIR data principles are followed.
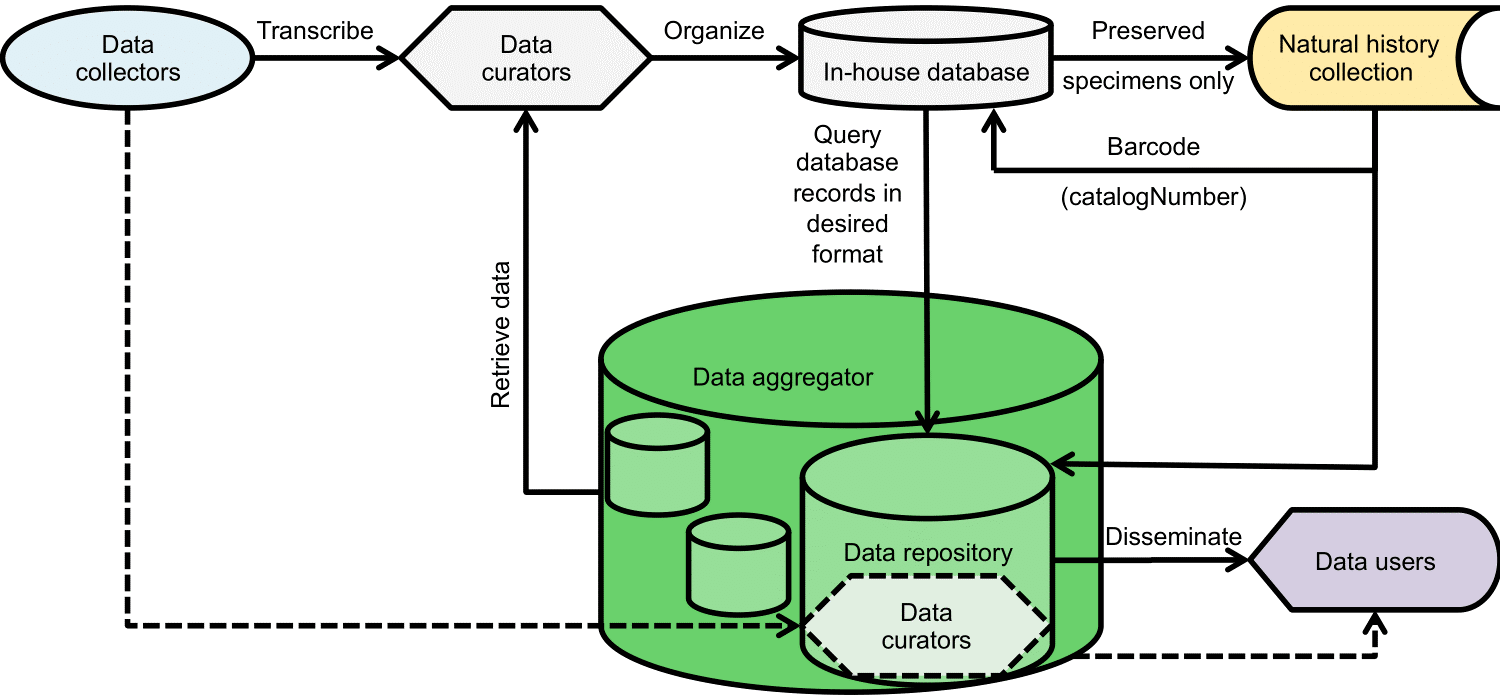
Figure 1. Generalized workflow describing the people, places, and processes involved in the transfer of data from the field to users. Dashed lines represent alternative pathways offered by some online data repositories.
My collaborators and I wanted to abide by FAIR data principles and increase the longevity of the data we were collecting in the field and compiling for our project partners and for future users. In A data management workflow of biodiversity data from the field to data users, we described our process (Figure 1), products, obstacles, and needs that could improve the adoption of FAIR data principles.
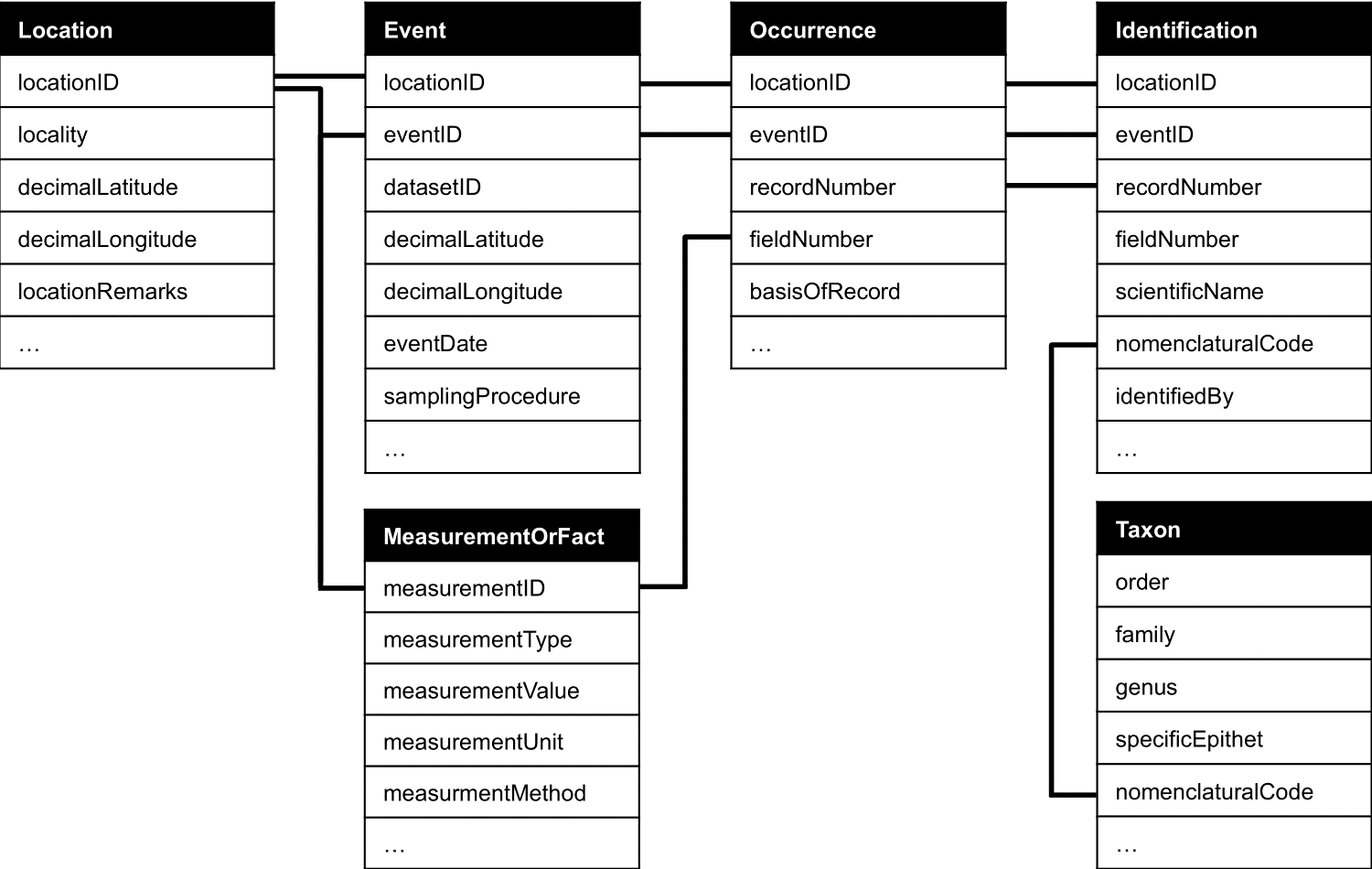
Figure 2. Relational in-house database. Each box with a black header represents a table in- cluded in the database. Each row in the boxes represents a field/attribute. Three dots (“…”) indi- cate that additional fields were not included for ease of viewing. Black lines represent common fields between tables that were linked for query capabilities. Darwin Core Standards were used for the table and field names (Wieczorek et al., 2012; Darwin Core Maintenance Group, 2014).
We made over 23,000 biodiversity occurrence records finable and accessible in GBIF and Symbiota SEINet portals (Belitz et al., 2018b; a; Central Michigan University Herbarium, 2019). Our communication with our partners throughout the process contributed to disseminating our data in mannors which were useful to them. For example, we developed plant species checklists in the Symbiota SEINet portal for our land management partners, so they could easily find data of their site. Prairie fen checklists have been used to review possible species to be encountered at a site before visitation. In our data curation, we used DarwinCore terms including MeasurementOrFact tables to organize data and manage meta-data to improve interoperability and reusability (Figure 2). We vouchered the identification ability of individual collectors with 1529 preserved specimens deposited in the Central Michigan University Herbarium to increase the validity, longevity, and future use of our data (Figure 3).

Figure 3. Common elderberry (Sambucus canadensis L.) collected and preserved to voucher the identification skills of our field data collectors and provide material for future scientific questions. The occurrence record for this specimen is findable and accessible online with additional media: http://midwestherbaria.org/portal/collections/individual/index.php?occid...
Our perspective was both that from a data collector and data user: we collected occurrence records across vegetative and Lepidopteran taxa from the field and additional historical Lepidopteran data from a variety of sources, including “dark data” sources, where data is not carefully indexed so it becomes practically invisible to potential future users (Belitz et al., 2018b; a; Central Michigan University Herbarium, 2019). We used GPS data dictionary tools, voice records, and written journals to collect data in the field (Figure 4). These methods had their advantages and disadvantages. Universally, the clearer the desired endproducts are prior to collection, the more effiecention collection and curation. We dedicated thought and research to utilitze standardized or common vocabulary and creating categorized measurements from information often collected in catch-all notes. This improved the efficiency of data curation and future findability of data.
Advancements in data collecting technologies since we started collecting field data have overcome some of the obstacles of data collection and curation we faced. The flexibility of generating relational tables and application of automatic and customized media filenaming schemes in GPS data collecting apps (e.g., ArcCollector, Survey123) can streamline data collection and reduce data curation time. Talk-to-text software have utility when working with voice recordings. Establishing standard vocabulary prior to data collecting is critical for efficient data collection, data curation, and findability, especially with voice recordings. With these advances in technology, there is a need to develop templates and open source code to organize field-collected data to facilitate the efficient dissemination of interoperable and reuseable data to the greater scientific community.
Our data lives on, contributing to future science education and research. Future users can find and use our human observation records and preserved specimens to study phenology, climate change, evolution, or genetics. Our data has also been used in educational modules to increase Biodiversity Literacy in Undergraduate Education (BLUE; Monfils et al., 2019). Following FAIR data principles helps ensure that your data has the most impact on science and management, by allowing future users to answer currently unthought-of questions using novel techniques.

Figure 4. Rachel Hackett collecting vegetative field data in a waterproof journal and plant specimens in an insulated tote. Photograph by AmeriCorps member Molly Gorman.
Literature cited
Belitz, M.W., L. K. Hendrick, M. J. Monfils, D. L. Cuthrell, C. J. Marshall, A. Y. Kawahara, N. S. Cobb, et al. 2018a. “Aggregated Occurrence Records of the Federally Endangered Poweshiek Skipperling (Oarisma Poweshiek).” Biodiversity Data Journal 6: e29081.
Belitz, M W, L K Hendrick, M J Monfils, D L Cuthrell, C. J. Marshall, A Y Kawahara, N S Cobb, et al. 2018b. “Aggregated Occurrence Records of the Federally Endangered Poweshiek Skipperling (Oarisma Poweshiek).” Dataset. 2018.
Central Michigan University Herbarium. 2019. “Prairie Fen Biodiversity Project. Occurrence Dataset.” GBIF.Org. 2019.
Chapman, Arthur D. 2005. “Uses of Primary Species-Occurence Data.” Copenhagen.
Cheruvelil, Kendra Spence, and Patricia A Soranno. 2018. “Is Catalyzed by Open Science and Team Science.” BioScience 68 (10): 813–22. https://doi.org/10.1093/biosci/biy097.
Hampton, Stephanie E, Sean S Anderson, Sarah C Bagby, Corinna Gries, Xueying Han, Edmund M Hart, Matthew B Jones, et al. 2015. “The Tao of Open Science for Ecology.” Ecosphere 6 (July): 1–13.
Heidorn, P Bryan. 2008. “Shedding Light on the Dark Data in the Long Tail of Science.” Library Trends 57 (2): 280–99.
Monfils, A., D. Linton, M. Phillips, and L. Ellwood. 2019. “Following the Data.” In Biodiversity Literacy in Undergraduate Education, /Groups/Blue_data. QUBES Educational Resources. https://doi.org/10.25334/Q4WF18.
Reichman, O. J., M. B. Jones, and M. P. Schildhauer. 2011. “Challenges and Oppor- Tunities of Open Data in Ecology.” Science 331: 703–5.
Soltis, P. S., G. Nelson, and S. A. James. 2018. “Green Digitization: Online Botanical Collections Data Answering Real-World Questions.” Applications in Plant Sciences 6: e1028.





