
Data Curation Profiles—An Information Science framework for data managers
-- Contributed by Wade Bishop and Kelly White, The University of Tennessee, School of Information Sciences
The volume and variety of data within iDigBio is known by anyone working with biocollections. In today’s data intensive science climate, it is becoming more widely realized that in order for data to be discoverable, accessible, and usable, both now and over time, it must be collected, documented, organized, managed, and actively curated in a standardized manner. The iDigBio project helps to increase the accessibility and discoverability of data by connecting the research community, collections community, citizen scientists, and the general public through outreach activities as well as help pave the way for long-term sustainability of the national digitization effort. The digitization of any information object increases the re-use possibilities and adds another chapter in the story of the life of the data.
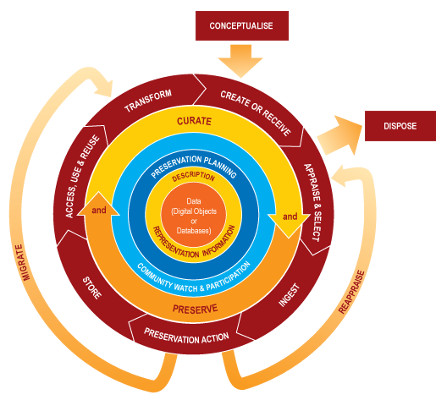
Data curation profiles (DCPs). DCPs give scientists, researchers, and data managers an enhanced and detailed understanding of the “data story” from the perspective of the data. A DCP “captures requirements for specific data generated by researchers articulated by the researchers themselves” (http://datacurationprofiles.org/purpose) and provides data managers a framework to acquire an in-depth understanding of the particular data curation needs of producers and their intended users. The DCP questionnaire includes questions related to (1) an overview of the research; (2) a description of the data, including number of files, size of files, and format of files; (3) the data flow and use in its creation, collection (i.e., how locality and time were determined), how the information representation such as naming conventions and metadata, as well as all the software used in all phases; (4) the data storage (i.e., data management and backups); and (5) the stakeholders, which includes intellectual property considerations and descriptions of the intended audience. The idea is that using a DCP will systematically collect all the potential information from the creators to prepare, maintain, and preserve data for posterity and reuse. For biocollections, DCPs could highlight areas in the data lifecycle that would benefit from further exploration or increased training.
Study. This study conducted DCPs for ten biocollections by interviewing data managers with an attempt to recruit across all fifteen NSF-funded Thematic Collections Networks (TCNs) active in 2015. The data managers consisted of three aggregators across TCNs, three herbarium managers, two paleontology managers, and two ichthyology managers. The participants were interviewed using the DCP questionnaire described above, recorded, and transcribed. The transcriptions were analyzed and themes coded in NVivo (Witt, Carlson, Brandt, & Cragin, 2009).
Findings. We found (1) DCPs of biocollections are diverse; (2) the DCP questionnaire would benefit from greater specificity when used by biocollection managers; and (3) managers of digital biocollections have different conceptualizations of stakeholders, including future users and their information needs and the long-term preservation of biocollections. Certainly, the first two findings are well known within the digitization community. The DCP presents a general framework, but DCPs of digitized specimens could include the common and known processes and software used in collecting biota. Those data managers in the study use the same information organization practices including the use of data dictionaries to ascribe scientific names to species (e.g., taxonomy hierarchies), analogous software to determine locality, globally unique identifiers for barcodes and database records, and time stamps to log any changes to the data and by whom. Metadata standards, data formats, and software across collections share many similarities. Further DCP work in biocollections could include profiling common data formats and types including images, field notes, locality forms, loan forms, and other ancillary files typical for particular specimens. In addition, DCPs did not scale well for aggregators and larger volume collections. This was partly because the average data file size and file counts in collections are a moving targets, but infrastructure considerations beyond an initial investment may require knowing size for storage considerations.
The data, its flow, use, and storage were easier sections of the DCP to address than questions related to stakeholders. The formulaic standardization in collection of biocollections is a great strength of these data. Several managers lacked specificity in the stakeholders portion of the questionnaire. For example, many managers defined the intended audiences for the data as only including other researchers in the field. A few outlined many other potential users and uses that if considered and included as audiences may inform curation approaches. A few managers were not certain who owned the data, but several knew exactly who owned what. As a social scientists new to the area, the discrepancy in approaches to ownership appears to be a barrier for use in a research area that requires sharing. Fortunately, all the aggregators follow stringent guidelines before ingesting data into more central repositories.
Conclusions. The results from this study showed that the DCPs of biocollections are already diverse with a uniqueness to each data story. The DCP questionnaire could benefit from a greater degree of specificity when used with biocollection managers, and that data managers could use the DCP to develop data management plans that address data dissemination, data deposit, data preservation, data discovery, and data repurposing in a systematic way. For the iDigBio community, everyone knows domain knowledge must be augmented with informatics. A diversity of solutions to capturing data collection details is a longstanding strength of bio, but using this information science framework for data managers adds the same level of standardization in the long-term sequential actions in the data lifecycle. Much of the work done on describing intellectual property rights, use constraints, and outlining how likely stakeholders will discover, access, and use particular collections is addressed in DCPs and injects a curation perspective at ingestion of data for both the creator and aggregators.
Bishop, B. W. & Hank, C. (2016). Data curation profiling of biocollections. Proceedings of the Association for Information Science and Technology, 53(1), 1-9. doi:10.1002/pra2.2016.14505301046
Witt, M., Carlson, J., Brandt, D. S., & Cragin, M. H. (2009). Constructing Data Curation Profiles. International Journal of Digital Curation, 4(3), 93–103. doi:10.2218/ijdc.v4i3.117
Special thanks to the participants in the study and the College of Communication and Information Dean’s Summer Research Support.





