
What: Visualize Your Text Data Using OCR Output
Why: Reveal the unexpected, get Fast access to your data
When: Wednesday 10 AM EST 22 January 2014
Where: http://idigbio.adobeconnect.com/augmentocrWho: All Are Welcome!
UPDATE Link to Webinar Report and Recording: DigBio Webinar: Visualize Your Text Data Using OCR Output
Note: Headsets recommended for best experience with AdobeConnect and please log in 15 minutes early if it is your first experience with AdobeConnect.
Twitter: @iDigBio #citscribe #ocrviz
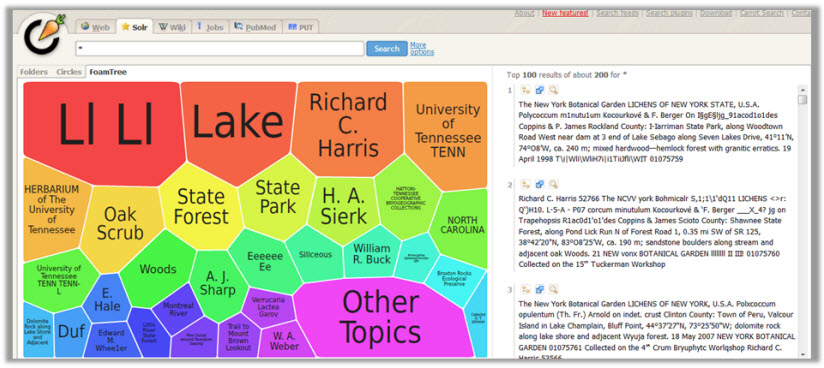
See your data in a whole new way! Museum specimen labels, note cards, field notebooks, ledgers and other primary source materials are being imaged in many digitization projects. New projects plan to OCR their materials or have questions about what they can do with the output.
OCR text output from these sources opens a window to your data, before the data elements are entered into the database fields. It gives you unprecedented, fast access to your data, revealing insights to facilitate research, data validation, and public participation in science. Come see a demonstration of how you might do this with OCR output. As part of the recent iDigBio CITScribe Hackathon, the LlLl team demonstrated one technique to do this visualization with Carrot2 and Google charts using OCR output indexed by Apache Solr and highlighting OCR errors using n-gram, a probabilistic model for estimating likelihood of a string being a good word. Find what you want, fast, and discover unexpected informative search terms. The same approach can be used to guide what needs to be validated using crowdsourcing outputs, on a per field basis. All are welcome.
See you there! Yes, please share the link, spread the word, and yes, it will be recorded.
Andrea, Jason, Miao, Sylvia, Reed, William, and @idbdeb from the @idigbio #citscribe LlLl Team, et al from the CITScribe Hackathon and iDigBio
NB: This work inspired by a Biodiversity Information Standards (TDWG) 2013 talk The use of OCR in the digitisation of herbarium specimens. Robyn Drinkwater, Robert Cubey, and Elspeth Haston, RBGE.
keywords: OCR ML NLP SOLR GoogleCharts CARROT2





